
【新智元导读】DeepMind公开了有关Veo 3视频模型最新论文!论文提出了「帧链」(Chain-of-Frames,CoF),认为视频模型也可能像通用大模型一样具备推理能力。零样本能力的涌现,表明视频模型的「GPT-3时刻」来了。
大模型的「零样本能力」,使自然语言处理从任务特定模型跃迁到了统一的、通用的基础模型。
这样的飞跃源于在规模数据上训练的大型生成式模型。
视频模型是否可以实现同样的飞跃,也向着具有通用视觉理解的方向发展。
在DeepMind近日发布的一篇论文中验证了这一猜想:
视频模型是「零样本学习者与推理者」,这一论点在足够强大的模型上几乎都能得到验证。

项目页面:https://video-zero-shot.github.io/
论文地址:https://arxiv.org/abs/2509.20328
研究证明,Veo 3可以完成大量它并未专门训练过的任务,比如:
物体分割、边缘检测、图像编辑、物理属性理解、物体可操作性识别、工具使用模拟等。
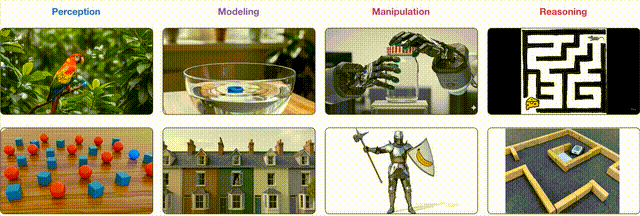
在多项视觉任务中,Veo 3涌现出零样本学习能力。这足以表明视频模型正朝着统一的、通用的「视觉基础模型」的方向发展——正如大语言模型成为语言基础模型一样。

谷歌发视觉版GPT-3模型
但无一作者来自美国
风险投资合伙人、谷歌搜索前员工、康奈尔计算机科学毕业生Deedy,对新论文推崇备至:Veo 3就是视觉推理的GPT-3时刻。
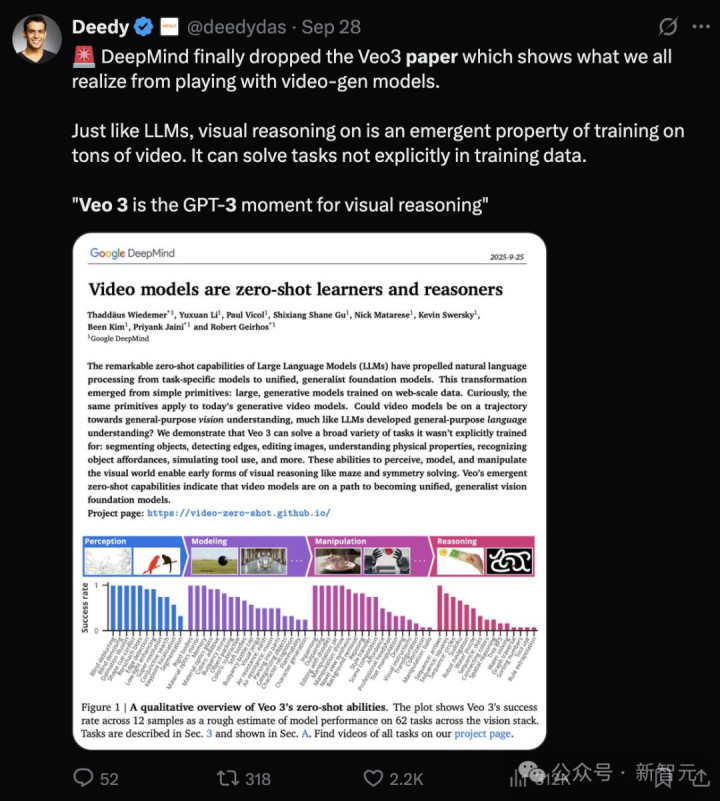
意外的是,随后Deedy发现论文作者中没有一个来自美国。
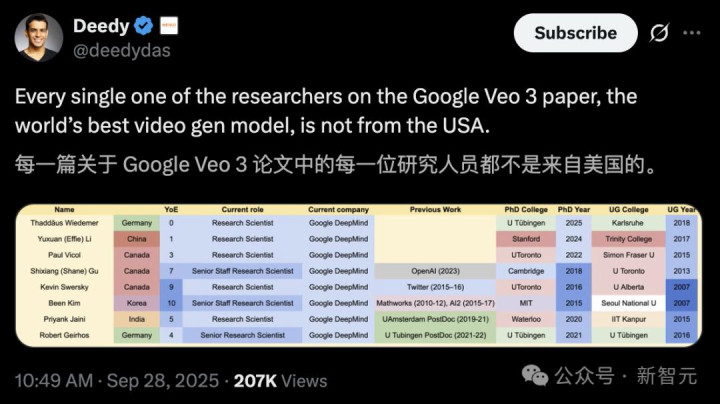
这8位研究者中,3位来自加拿大,2位来自德国,来自中国、韩国、印度各一位。
这篇「GPT-3」级别的论文的作者,没有一个来自美国,而且没有一个人在美国完成本科教育。哪怕算上博士毕业院校,美国也只有两所。
这不禁让网友怀疑:美国科研真不行了吗?
论文第一作者谷歌DeepMind实习生、在读博士生Thaddäus Wiedemer澄清道:
新论文只是评估了Veo和Gemini团队实现和训练的模型。

也就是说,Veo 3主要是由其他团队实现和训练的,新论文≠Veo 3。
这篇论文和OpenAI的GPT-3论文,在标题上具有极大的相似性,但谷歌新论文作者对Veo 3的实际贡献明显
尽管GPT-3论文的核心在于证明了语言模型的少样本学习能力,但论文作者的确训练出GPT-3。

论文链接:https://arxiv.org/abs/2005.14165
Thaddäus Wiedemer还指出,这项工作是在DeepMind多伦多完成的。
这就解释了为什么来自加拿大的作者最多——
近水楼台先得月,多伦多本地的加拿大人参与此项研究的机会更大。
不过,值得一提的是,Thaddäus Wiedemer在清华大学从事过约1年的研究实习。

此外,第二作者Yuxuan (Effie) Li来自国内;作者Shixiang Shane Gu则是华裔加拿大人。
视频模型是零样本学习者和推理者
大模型日益展现出「零样本学习」所衍生出的解决新任务的能力。
所谓零样本学习,即仅通过提示词指令即可完成任务,无需微调或添加任务特定模块。
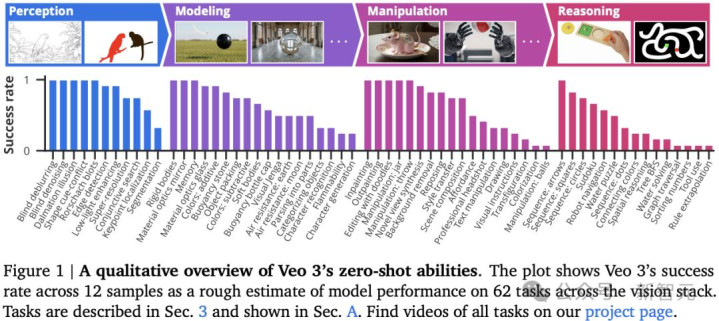
研究人员通过分析18,384个Veo 3生成的视频,在62个定性任务和7个定量任务中,发现它可以完成多种未曾训练或适配的任务:
凭借感知、建模和操控视觉世界的能力,Veo 3展现出「帧链式(Chain-of-Frames, CoF)」视觉推理的初步能力。
虽然目前的任务特定模型性能仍优于零样本视频模型,但研究人员观察到Veo 3相比Veo 2在表现上有显著提升,这表明视频模型能力正在快速演进。
研究人员采用的方法很简单:向Veo模型提供提示词。
为何选择Veo?
研究人员之所以选择Veo,是因为它在text2video和image2video排行榜中表现突出。
为展现性能进步的速度,研究人员还将Veo 3与其前代Veo 2进行对比。
研究人员对多个视觉任务进行了广泛的定性研究,以评估视频模型是否具备作为视觉基础模型的潜力,并将发现归纳为四个层级能力体系,每一层都在前一层基础上演化而来(见图 1 和图 2):
感知:理解视觉信息的基本能力
建模:在感知物体的基础上对视觉世界进行建模
操控:对已建模的视觉世界进行有意义的修改
推理:跨时间与空间的视觉推理能力

建模直觉物理与世界模型
视频模型在感知视觉世界的基础上,开始尝试对其进行建模。
对世界及其运行原理(例如物理定律)进行建模,是实现有效预测与行动的关键一步。
目前,已有多项研究在深度模型中探索并量化了直觉物理能力,论文中节选了其中部分具有代表性的任务进行分析。
比如,Veo对物理规律的理解,体现在其能够建模刚体与软体的动力学以及它们之间的表面交互。
Veo还展现了对多种物理属性的认知,例如可燃性、空气阻力对下落物体的影响、浮力、光学现象等。
除了物理属性,Veo还理解抽象关系,这对于建模现实世界也至关重要。
例如,Veo能够区分玩具与笔记本电脑等其他物品。
研究人员还展示了Veo在识别模式、生成变体以及将整体结构拆解为部分等方面的能力。
此外,Veo还能在视频中跨时间与镜头变化维持对世界状态的记忆。
从「思维链」到「帧链」
Veo能够感知物体,并建模它们之间以及与环境的关系,因此它也具备对视觉世界进行有意义操控的能力。
感知、建模与操控的能力相互融合,共同构建起视觉推理的基础。
与语言模型操控文字符号不同,视频模型可以在真实世界的两个关键维度——时间与空间中进行操作。
这一过程类似于语言模型中的「思维链」(Chain-of-Thought,CoT),研究人员称之为「帧链」(Chain-of-Frames,CoF)。
研究人员认为,在语言领域中,思维链使模型能够解决推理类问题;同样帧链(也即视频生成)或许也能帮助视频模型解决那些需要跨时间和空间逐步推理的复杂视觉问题。
尽管模型的表现尚不完美,但其在零样本条件下解决这些问题的能力,展示了未来更强大视频模型在视觉推理和规划方面的巨大潜力。
定量评估
在对视频模型的能力做了定性研究之后,研究人员从七个具体任务出发,对其进行定量评估。
从视觉理解的不同方面来考察模型表现:
感知能力:评估Veo在边缘检测、图像分割和目标提取方面的能力;
操控能力:测试其在图像编辑方面的表现;
推理能力:通过迷宫求解、视觉对称性和视觉类比任务来评估。
边缘检测
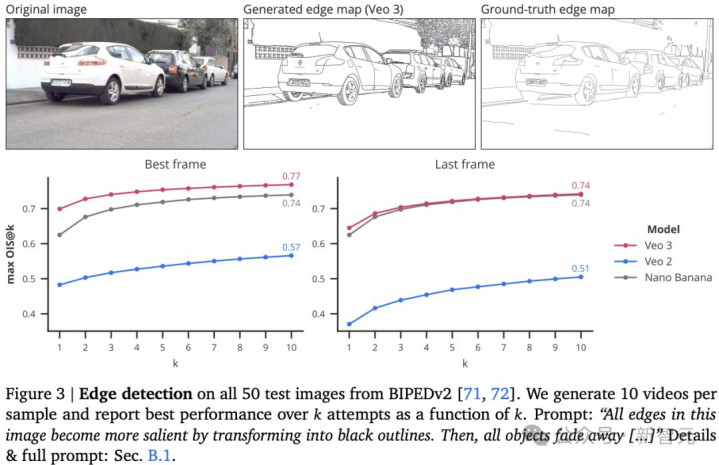
研究发现,即便没有专门为边缘检测任务训练,Veo 3仍然可以通过提示词实现边缘感知。
图3展示了Veo 2和Veo 3在边缘检测任务上的表现。
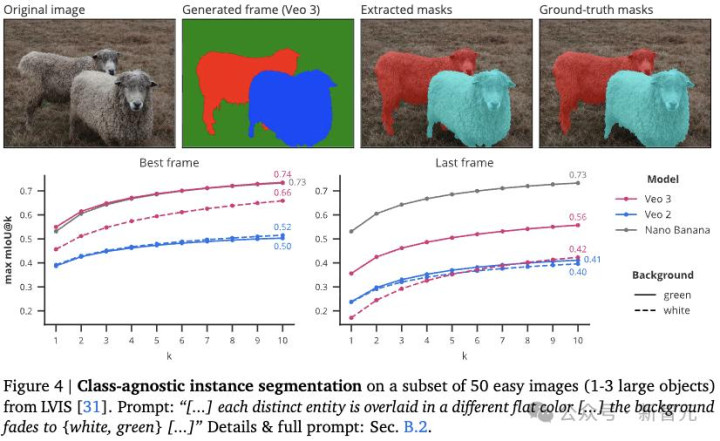
图4显示在LVIS数据集的一个包含50张简单场景图像(每张图像中含有1到3个大型物体)的子集上进行类别无关的实例分割。
图像分割
与经典的实例分割或可提示分割不同,研究人员提示模型分割场景中的所有物体,而不指定物体类别或位置。
如图4所示,Veo 3实现了0.74的mIoU(最佳帧 pass@10),与Nano Banana的0.73 相当。
当然,Veo 3的性能落后于像SAMv2这样的定制模型,但仍然展示了卓越的零样本分割能力。
物体提取
研究人员要求Veo提取并将所有动物排成一排,彼此之间用白色背景分隔,通过统计最后一帧中连接组件的数量,来判断提取的动物数量是否正确。
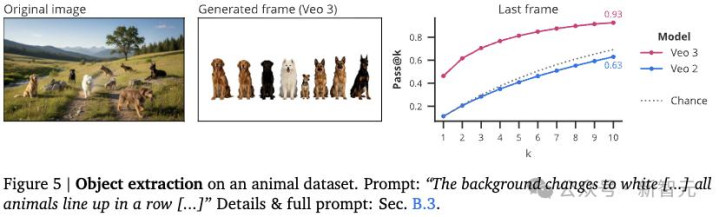
图5展示了示例和实验结果。Veo 2的表现接近随机,而Veo 3的pass@10最高可达92.6%。

图6展示了一个编辑示例和评估结果,研究人员发现Veo 3尤其擅长在编辑过程中保留细节和纹理。
迷宫求解
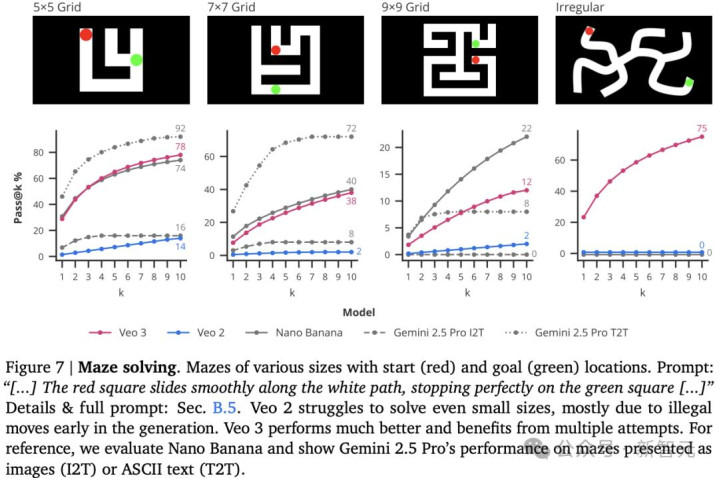
在图7的迷宫求解中,各种迷宫标有起点(红色)和终点(绿色)位置。
Veo 2即使在求解较小规模的迷宫时也表现不佳,这主要由于生成过程中早期出现了非法移动,Veo 3 表现得更好。
总体来看,视频模型具备对数字视觉世界进行操作与模拟的能力。
图像编辑
图像编辑,是指根据文本指令对图像进行操作(例如添加、移除物体或更改外观)。
研究人员在Emu-edit数据集的一个随机子集(共 30 个样本)上评估了Veo的图像编辑能力。
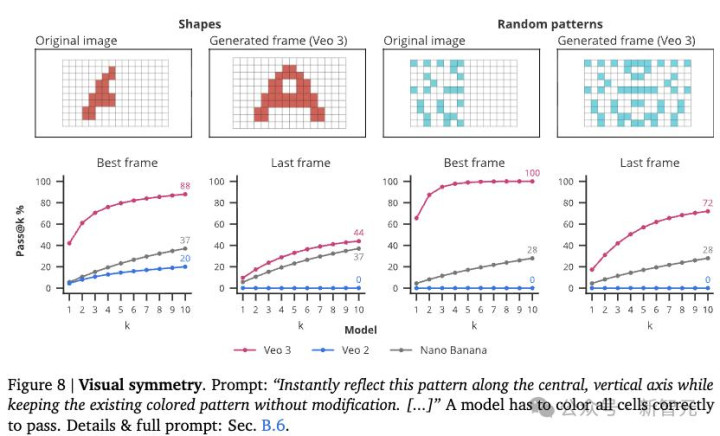
图案对称补全任务用于评估模型对空间推理的理解与应用能力。图8显示,在这方面Veo 3的表现远超Veo 2和Nano Banana。
视觉类比任务用于评估模型理解物体变换及其关系的能力,属于抽象推理的一种形式。
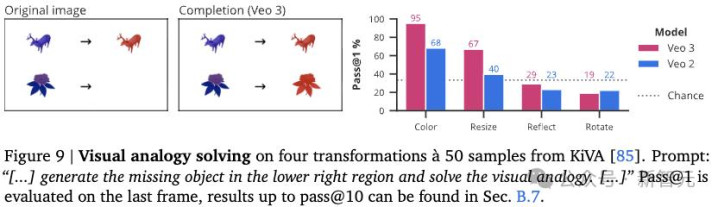
图9显示,尽管Veo 2在理解类比任务方面表现不佳,Veo 3能够正确完成颜色变化和尺寸变化的样例。
然而,在镜像和旋转类比上,两种模型的表现均低于猜测水平(0.33),表明存在系统性错误偏差。
视觉领域的 「GPT-3 时刻」
近年来,自然语言处理(NLP)领域的发展尤为迅猛。
这一趋势由通用型大模型的崛起所推动,其在零样本学习场景中解决新任务的能力,已使其取代了NLP中大多数的特定任务模型。
研究人员据此提出一个观点:机器视觉也正处于类似的范式转变临界点,这一变革由大规模视频模型所展现的涌现能力所驱动。
本论文的核心发现是:
Veo 3能够以零样本方式完成各类任务,涵盖从感知、建模、操控,甚至到早期的视觉推理等整个视觉技术栈。
尽管其性能尚未尽善尽美,但Veo 2到Veo 3所展现出的显著且持续的性能提升,表明视频模型很有可能像语言模型之NLP一样,成为视觉领域的通用型基础模型。
股票如何开杠杆,新宝策略,玛世配资提示:文章来自网络,不代表本站观点。



